12th November 2016

A few weekends ago Jan Ainali, Lars Lundqist, Ulrika Nilsson, David Zardini and myself attended the Hack4Heritage hackathon in Stockholm. We ended up creating the site Kyrksok.se, a directory for churches in Sweden.
Kyrksök links together various sources such as Wikipedia, Commons and Bebyggelseregistret and makes their content more accessible and discoverable.
Setting up a site and display content is never that interesting or much of a challenge not even if there is content from a lot of different sources as long as there is links between them.
Guess what,
there was no such links,
Luckily Wikidata is a perfect place to link all the datasets together.
Actually most of the time spent on Kyrksok was spent on linking Bebyggelseregistret to Wikidata and on the existing data, mostly common tasks such as normalizing labels and verifying existing statements and links.
Once all the third-party URIs was in Wikidata, we could fetch a list of churches which had the required data using Wikidatas SparQL endpoint(Kyrksok query: visualized/source).
By using Pywikibot and KSamsok-PY we could then index data from all the data sources we needed without much work. Everything was indexed to a SQLite file. That’s mainly it, we had by then a great dataset indexed form a bunch of different sources.
We then fired up a rest API(Python/Flask) for this SQLite file with both search/bounding box methods, still this API is made in less the 80 lines of code. Just check it out.
The best thing about this is that this approach can be applied to any idea, the data in Wikidata is extremely diverse. Wikidata has become a incredible important source for many of the project I’m involved in including Biocaching.
Go ahead and check out all the Kyrksök repositories over at Github.
(Kyrksök = “church search”)
3rd November 2016
The main Biocaching client biocaching.com is built with PHP and I was the one responsible for the decision to do it that way.
Although the Biocaching Platform is API first, biocaching.com is not all client side JavaScript. Development speed, easy accessibility, rendering speed and maintainability was all reasons to ditch the idea.
I considered both Go, Ruby and Node. Node had the advantage of being non-blocking by default. Rails had the advantage of development speed and of being Ruby(Ruby is used all over Biocaching). Go is just not there yet, wasn’t there a new package loading solution the other day?
PHP had the advantage of development speed and the fact that’s literary made for HTML rendering. No framework needed, the best documentation around and it’s easy for anyone to maintain.
Just yesterday I was trying to get the TTFB(time to first byte) decreased on profile pages over at biocaching.com, usually the TTFB is not a issue in most applications but the biocaching.com server application is an API first application making actual HTTP request to the Biocaching API...
If you are now thinking how stupid it is to use a blocking language such as PHP for such an application you should do a few Google searches and end up on Stack Overflow a few times.
Aka general development work-flow.
So the reason for the issue on biocaching.com was my logic for rendering all the follow buttons(there can be a lot of them).
I started of with my calculator as usually when working on performance issues, did some analytics and decided on a solution that could reduce the TTFB up to 37%!
Let’s just say that my calculation sucked, I was at one point able to measure a improvement at 87%. It’s milliseconds but still magic.
If you would like to see more posts about the Biocaching Platform, the sometimes crazy technical solutions and the usage of some of the coolest open datasets around let me know!
24th September 2016
Update Platsr.se does no longer exists.
Platsr.se if you aren’t familiar is a web community for gathering local stories and media around different locations. As a result it got some pretty incredible data, which users have put a lot of thought into, all available under open licenses.
Platsr also got a API and have been having one for ages, but almost no one has created upon it. If you take a look at the official documentation you won’t find that fact weird(even if you do read Swedish).
Only because you provide an open API you do not make it accessible. Actually, you can throw huge piles of money into developing an amazing API and developers will never end up using it anyway.
Creating Something Useful
I decided to rewrite the Platsr API documentation and create an API Sandbox for it.
When I set off to build the sandbox my feature specification was as basic as the following:
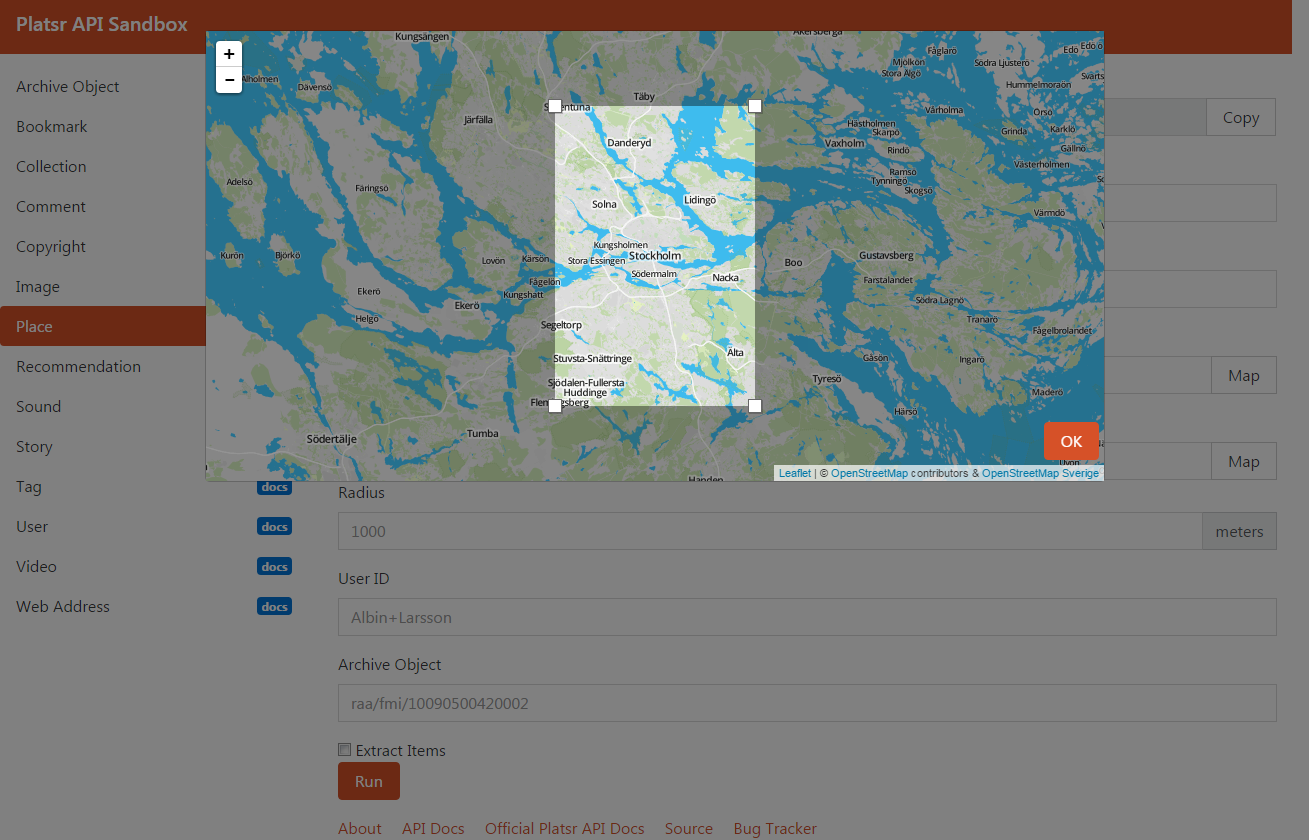
- Visual interface for geographic queries, bounding boxes, etc.
- Tied closely with the documentation for usability.
- Only relevant parameter fields for your specific query should be displayed.
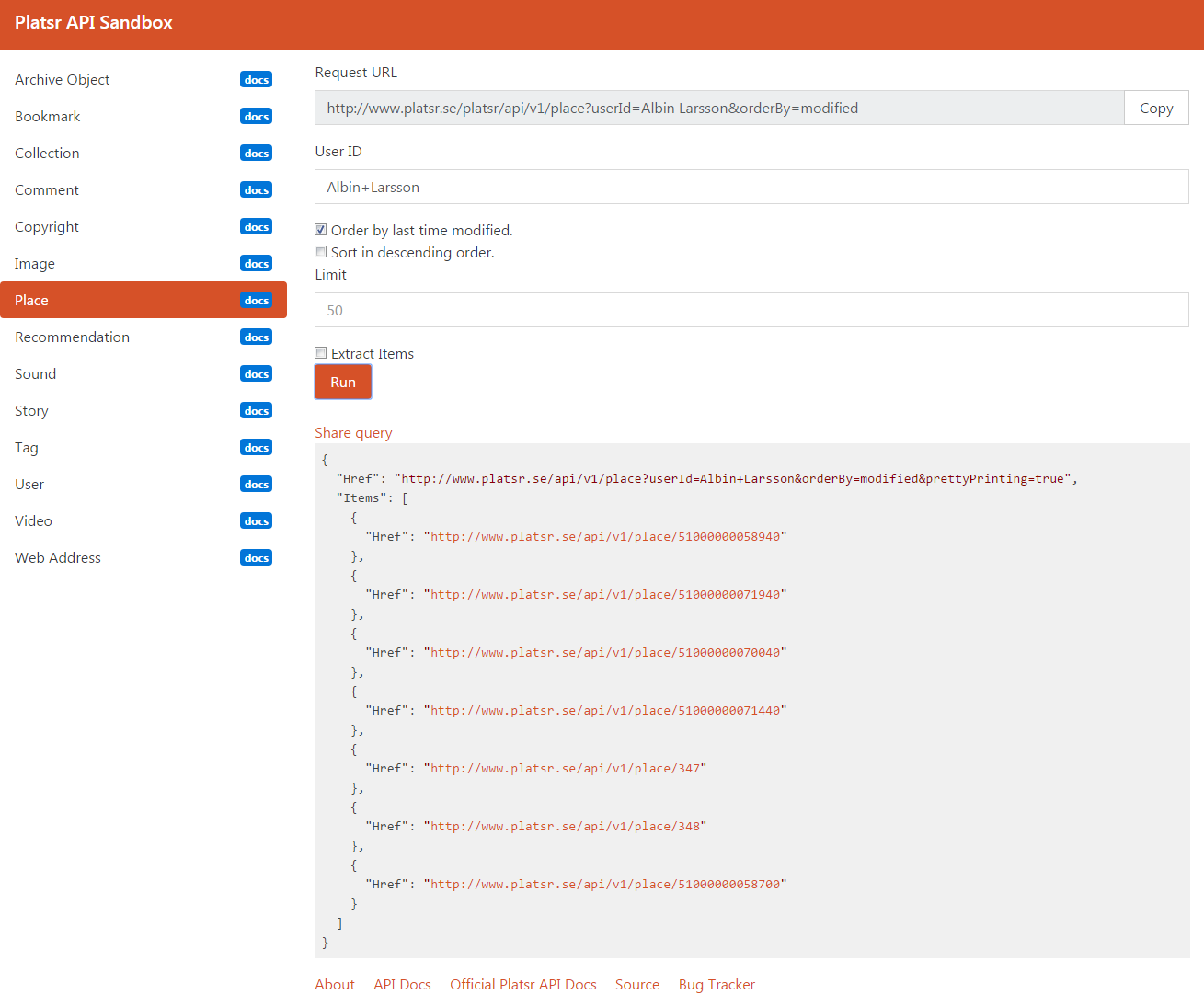
- Users should be able to share queries with direct links.
- Resources within the response body should link to its sandbox query.
Rewriting all the documentation from scratch took a train trip between Oslo and Katrineholm(roughly five hours). Nothing the original developers could not have invested in from the beginning.
Building the sandbox on the other hand took a lot more time than it would have taken me to write the actual API.
It required a proxy server to avoid CORS and Mixed Content issues, because who uses your API clientside and prefers HTTPS? ;-)
In the end I ended up being relay happy about the end result, you can try the sandbox out and access the documentation right now. Please let me know what you think so I can make even better sandboxes and documentation next time!
Tip: When developing APIs write the documentation first then use it as a blueprint for the actual development.
Want to chat?
Would you like to talk to me about open data/data accessibility, hacks/projects, or anything else?
I will be attending both Hack4Heritage in Stockholm and Hack4NO in Hønefoss, make sure to catch me there!
Some previous posts that might interest you:
8th February 2016

I got home late yesterday after an entire weekend at Hack4FI - Hack your heritage in Helsinki. This was a very different hackathon for me, because I was there as a part of Wikimedia Finlands Wikidata project and had no intention at all to work on any specific project. The only aim I had was to promote Wikidata/Wikimedia and help with actual technical things as much as I could.
I found myself in a total new position where I was the person people pointed at if anyone had questions and the person people from different institutions ask about Wikidata/Wikimedia. I tried my best answering everyone and helping people create integrations. I know that we got a few people working on bots and integrations and a few organizations/institutions to start using Wikidata. I’m hoping I can continue be a support for both the organizations and individual developers, if I don’t know the answer to a question that just means that I will learn something new and that’s what I love!
I’m happy to see so many museums and other institutions opening up, many of them seams to have the process of copy and pasting values from a spreadsheet into Wikidata and Wikimedia Commons, aka there is a need for huge need for GLAM developers!
Ajapaik2Commons
Actually I did a bit of actual coding for a project. Ajapaik2Commons could be completed in just two hours and was a nice way of ending the weekend. Ajapaik2Commons is a tool for taking a rephotograph from Ajapaik.ee and publish it on Wikimedia Commons with all of its meta data. Ajapaik2Commons is based on the Mapillary2Commons tool made by André Costa and it uses the URL2Commons tool by Magnus Manske behind the scenes. It can be used by other tool passing a Ajapaik id through a URL parameter.
Currently it’s isn’t online, I’m going to publish it on the Tool Labs Server as soon as I got the time to look into how it works(got access almost direct after my request, amazing admins!), maybe I have the time on Wednesday!
Special thanks to Wikimedia Finland who made my participation possible! Keep on learning together everyone!