21st January 2025
I’m very fond of Git work trees, but I’m rather opinionated regarding the directory structure of my projects. I prefer a “root” project directory containing my .git and all my work trees next to it. Like this:
my-project
.git
main
feature-branch-1
bug-branch-398
To accomplish the above with git clone you need to go through a few steps:
- make a bare clone into given both the Git URI and the directory you want to clone it into
- lookup the name of the default branch
- add the work tree of said branch
That might not be a lot of work, but I care quite a lot about reducing friction, so I turned the above into a Fish shell function.
function git_clone_work_tree -d "make a bare clone of the given repository and creates a work tree for the default branch"
set repository_url $argv[1]
set repository_name $(basename $repository_url .git)
git clone --bare $repository_url $repository_name/.git
cd $repository_name
set default_branch $(git remote show $(git remote) | awk '/HEAD branch/ {print $NF}')
git worktree add $default_branch
end
It’s as simple as:
git_clone_work_tree https://github.com/glaciers-in-archives/snowman.git
Which results in a directory structure:
The same friction occurs when I need to turn a simple directory of files into a Git repository following the same directory convention. The following function moves the project initiates a bare repository adds a new work tree and moves all the project files there:
function git_init_work_tree -d "move the current directory to a child directory and make it the default branch in a new repository"
set reopository_name $(basename $(pwd))
set default_branch $(git config --get init.defaultBranch)
git init --bare .git
git worktree add --orphan $default_branch
mv (ls -A | grep -v '^\.git$\|^'"$default_branch"'$') $default_branch/
end
These two shell functions make it much easier for me to accomplish a “Git work tree first” workflow as they are as easy as the initial Git commands and ensure Git work tree usage down the line does not pollute my parent directories.
21st October 2024
I finally got(took) the time to automate away the 2 seconds it takes me to set up my Konsole development layout. Given the sparse examples showing Konsole’s DBus interface and its quirks in action, I thought it made sense to share my script here.
Having recently moved from Bash to Fish, I rediscovered the joy of shell scripting and added some git and just checks as well.
The following Fish function results in a three-pane window with Vim to the right taking up 65% of my screen leaving two top-to-bottom split panes showing potential information from git or just.
function git_summary -d "check if you are in a git repository and show git-related information"
if git rev-parse --is-inside-work-tree >/dev/null 2>&1
git status
git worktree list
else if test -d .git
git worktree list
end
end
function just_summary -d "check if a justfile exists and list the available commands"
if test -f justfile
just --list
else
echo "No justfile found"
end
end
function dev -d "From the existing session setup a three-pane layout with git status, nvim, and just --list"
# Setup layout
set PRIMARY_SESSION_ID (qdbus $KONSOLE_DBUS_SERVICE /Windows/1 org.kde.konsole.Window.currentSession)
qdbus $KONSOLE_DBUS_SERVICE /konsole/MainWindow_1 org.kde.KMainWindow.activateAction split-view-left-right > /dev/null
set EDITOR_SESSION_ID (qdbus $KONSOLE_DBUS_SERVICE /Windows/1 org.kde.konsole.Window.currentSession)
qdbus $KONSOLE_DBUS_SERVICE /Windows/1 org.kde.konsole.Window.setCurrentSession $PRIMARY_SESSION_ID
qdbus $KONSOLE_DBUS_SERVICE /konsole/MainWindow_1 org.kde.KMainWindow.activateAction split-view-top-bottom > /dev/null
set SECONDARY_SESSION_ID (qdbus $KONSOLE_DBUS_SERVICE /Windows/1 org.kde.konsole.Window.currentSession)
# NOTE: qdbus does not appear to work with the resizeSplits method: https://invent.kde.org/utilities/konsole/-/merge_requests/932#note_837270
gdbus call --session --dest $KONSOLE_DBUS_SERVICE --object-path /Windows/1 --method org.kde.konsole.Window.resizeSplits 0 "[35, 65]" > /dev/null
qdbus $KONSOLE_DBUS_SERVICE /konsole/MainWindow_1 org.qtproject.Qt.QWidget.showFullScreen
# Finally run the various commands in the right panes
qdbus $KONSOLE_DBUS_SERVICE /Sessions/$EDITOR_SESSION_ID org.kde.konsole.Session.runCommand "nvim ."
qdbus $KONSOLE_DBUS_SERVICE /Sessions/$PRIMARY_SESSION_ID org.kde.konsole.Session.runCommand "git_summary"
# TODO: it seems like bash is always initiated before fish, for an unknown reason
set FUNCTION_FILE (status --current-filename)
qdbus $KONSOLE_DBUS_SERVICE /Sessions/$SECONDARY_SESSION_ID org.kde.konsole.Session.runCommand "fish -c 'source $FUNCTION_FILE; just_summary'"
end
Note that $KONSOLE_DBUS_SERVICE is only available from Konsole itself, some alternatives are available as per the Konsole manual. I wasn’t able to get qdbus to work with Qt arrays so I used gdbus(I’m on a Gnome-based system but I prefer the syntax of qdbus.). It’s odd that in my final panel, I need to run fish manually as my default shell is fish, I’m a little worried that there is an underlying problem.
5th August 2024
You have just deployed your 55th reconciliation service for a MediaWiki or Wikibase-based service. You start wondering if this isn’t the time to stop copy-pasting your code around and apply some of that don’t-repeat-yourself wisdom. That was me a moment ago after a few months of pushing it in front of me. Now a prototype intended to replace all of our reconciliation services targeting MediaWiki and Wikibase is here and you can give it a go in OpenRefine!
Let’s jump in head first with some example endpoints:
https://kartkod.se/apis/reconciliation/mw/en.wikipedia.org/ # English Wikipedia (MediaWiki)
https://kartkod.se/apis/reconciliation/wb/wikibase.world/ # Wikibase World (Wikibase)
https://kartkod.se/apis/reconciliation/wb/www.wikidata.org/ # Wikidata (Wikibase)
https://kartkod.se/apis/reconciliation/mw/www.wikidata.org/ # Wikidata (MediaWiki)
https://kartkod.se/apis/reconciliation/mw/en.wikisource.org/ # English Wikisource (MediaWiki)
# your wiki? and many more!
You see the patterns, now let’s see how we got here. Once you realize you can put any domain in there, you might think that we made it very error-prone and complex. We did, here is why:
It’s not error-prone to us
You see, our OpenRefine users can’t add their own reconciliation services and our collection of services is already there the first time they sign in.
We want it to be open to you
If we needed to allow-list all the configurations it would quickly become less useful to others and we need it to hook into our other reconciliation services with local restrictions anyway. It’s an experiment and I hope we can keep it configuration less.
We need it to be stateless
We deploy all our reconciliation services in a distributed way and keeping our services stateless is incredibly useful to limit the maintenance and engineering needed.
Future work
This service is experimental and you should expect it to change in the coming weeks as we bring it on pair with our existing services. It will never implement the whole Reconciliation specification but
- Wikibase reconciliation beyond items(properties are especially important)
- Documentation on how to reconcile against specific namespaces
- Documentation on how to reconcile against Wikibase items with certain statements
- Error messages and service validation(things that aren’t MediaWikis, things without necessary extensions, etc)
- Auto generation of usage documentation based on installed extensions(CirrusSearch, etc)
- Support Wikimedia Commons entities(it’s a weird one and given the state of Structured Data on Commons it’s not highly prioritized)
A note on compatibility with the OpenRefine Wikibase extension, our reconciliation services consider the Wikibase URIs as the “true” identifiers while the Wikibase extension expects just the QID. Hopefully, this is something I can work on upstream as it’s not an option to change the behavior on our end. In the meantime you might be able to work around this using the “Use values as identifiers” feature.
I hope you give it a try, if you have any questions or suggestions feel free to reach out. I will also be at Wikimania if you want to chat in person!
19th July 2024
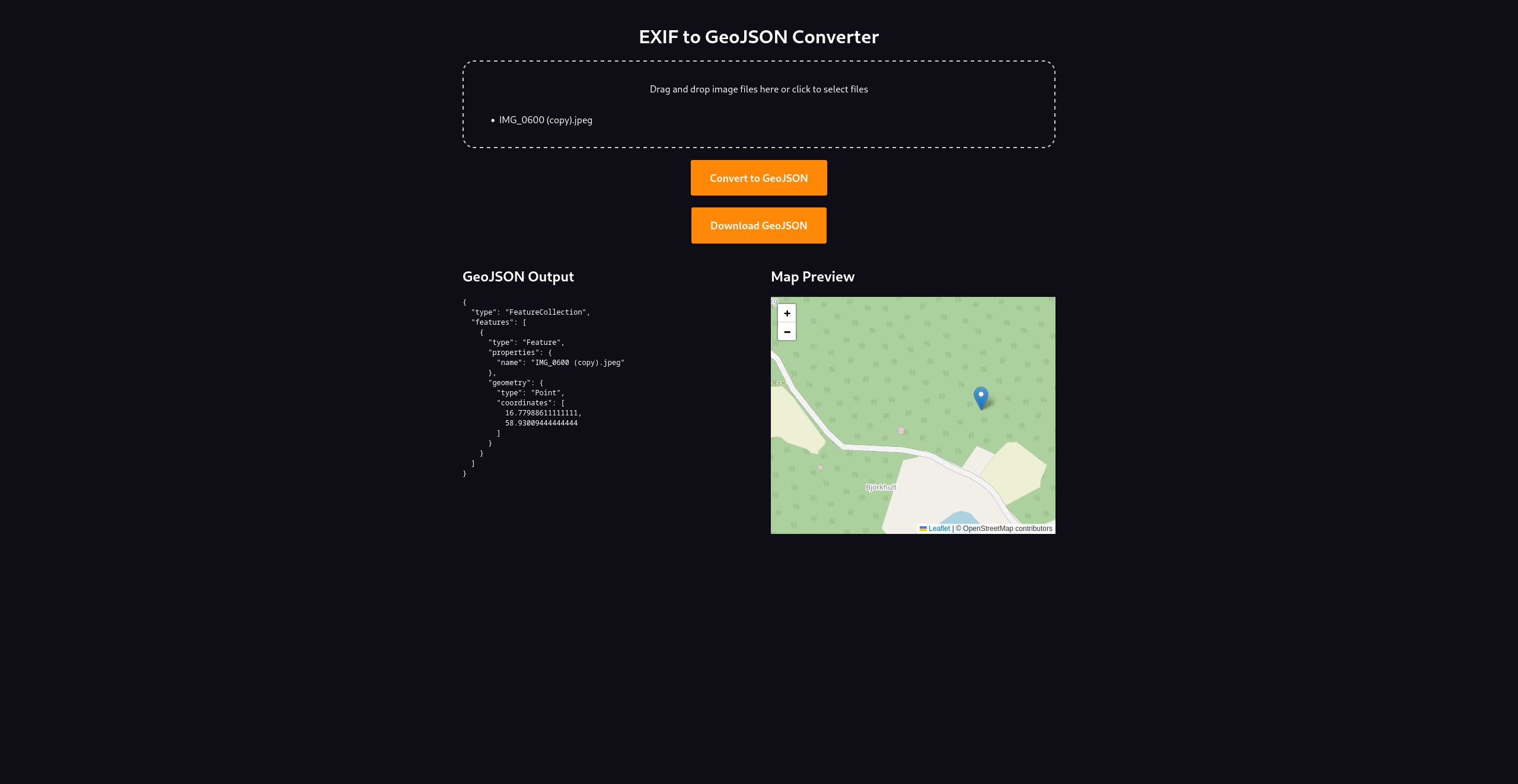
I made a small tool for extracting EXIF location data and “converting” it into GeoJSON. It comes from my need to display EXIF locations in OpenOrienteering Mapper. Turns out it’s useful for other things like OpenStreetMap mapping and Wikidata(WikiShootMe supports custom GeoJSON layers).
You find the tool on this webpage and the code over at Codeberg.