31st March 2017
Update Github now supports SSL for custom domains.
One of the downsides with hosting this site on Github Pages has always been the lack of SSL support. From a SEO perspective it’s supposed to be important(I have no clue), it’s not a major thing for me people usually do not end up here after a Google search.
The main downside is that there is a bunch of cool (not so)modern web APIs such as Service Workers and Geo-location which does not work on insecure connections.
Cloudflare acts as a service between the users and the actual server, serving static content. This approach is perfect for Github Pages. This way content served through Cloudflare can be given a SSL certificate without the need for one between Github Pages and Cloudflare. This setup comes with a downside in the form of cache, because Cloudflare caches all content we do need to purge the cache when we make any changes to our site(such as this post). Github webhooks and the Cloudflare API is your friends.
Expecting a tutorial here? There is no need for one, I have never seen a better on boarding at any DNS provider. Create an account and enter you custom domain name, your DN-records will be imported and you will be assigned two name servers. Just a minor note, in the SSL settings you should select the “full” option and not the “flexible” one.
Now for even cooler demos :-)
2nd February 2017
 The women relay flower ceremony(Maiken Sandberg, CC BY-SA 4.0).
The women relay flower ceremony(Maiken Sandberg, CC BY-SA 4.0).
In front of and during the World Orienteering Championships last year I was a member of the media team. My objective was to write (almost)real time route analytics and comments during the races.
A few weeks before the event one of the persons responsible for outreach asked me if I could update some of the outdated articles on the Swedish Wikipedia. I said “sure”. I could need some more experience actually editing Wikipedia.
Prior to this the Swedish Orienteering Federation had updated their site(“big event, lot of exposure - lets update our site”). Guess what, they broke all their links.
Once my bot was done updating them all I could start editing. When the championships started most of the relevant biographies was up to date.
At this point I started to improvise a small project, I convinced a key member of the media team that it would be a good idea to publish images taken by the media team under open licensing so they could be used on Wikipedia. Because it was so close upon the event and so improvised I had to chat with all of the different authors and import the images from the official image gallery on my own.
I did the last batch upload just a few days ago and now I have uploaded more than 240 images(including logos), not a large number but for a one man project reaching beyond what I usually do, I’m happy with the result.
There is of-course a lot I would do in another way next time(when it’s not improvised). At least next time I will be able to give an example of a media team at a major sport event which worked with Wikimedia Commons.
Checkout the World Orienteering Championships 2016 category to have a look at the images.
 Tove Alexandersson running towards the gold medal during the middle distance(Klas Bringert, CC BY-SA 4.0).
Tove Alexandersson running towards the gold medal during the middle distance(Klas Bringert, CC BY-SA 4.0).
12th December 2016
Recently there has been multiply discussions about the connections between Wikidata and OpenStreetMap. Many Wikimedians has been concerned about the one way connection through the wikidata tag over at OpenStreetMap and the lack of a way to find the corresponding OpenStreetMap element from within Wikidata.
The easiest way in the past has been to head over to Overpass Turbo and query for the Wikidata id. I would say that even for OSM folks and SparQL hippies it’s a bit of an annoying process.
Because of this I created a Wikidata UserScript a while ago witch adds a link to the OpenStreetMap Element which has the Wikidata id referenced.
You can try it out by adding the following line to your common.js file:
importScript('User:Abbe98/osm.js');
Behind the scene it’s using the Overpass API for looking up the OSM element, it’s source is available over at Github.
28th November 2016
There is tons of georeferenced maps over at Wikimedia Commons and the Wikimaps Warper and earlier this year we added the ability to retrieve the georeferenced data from the Warper by the Commons page ID. This allows developers and others writing UserScripts and Gadgets to fetch Warper data directly from Commons.
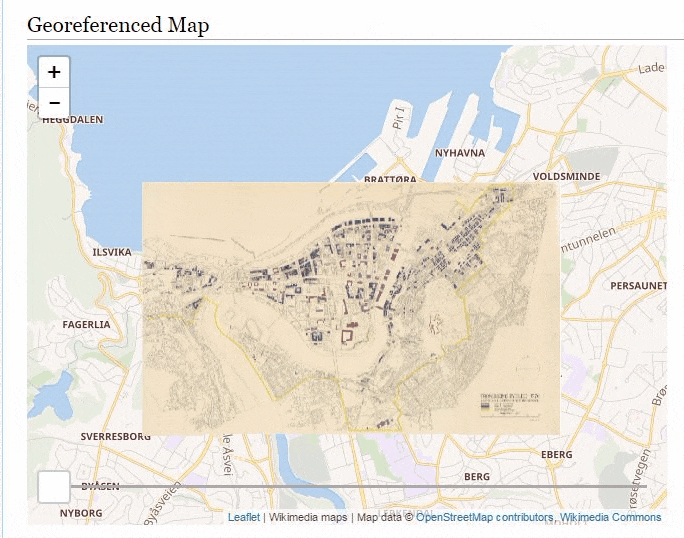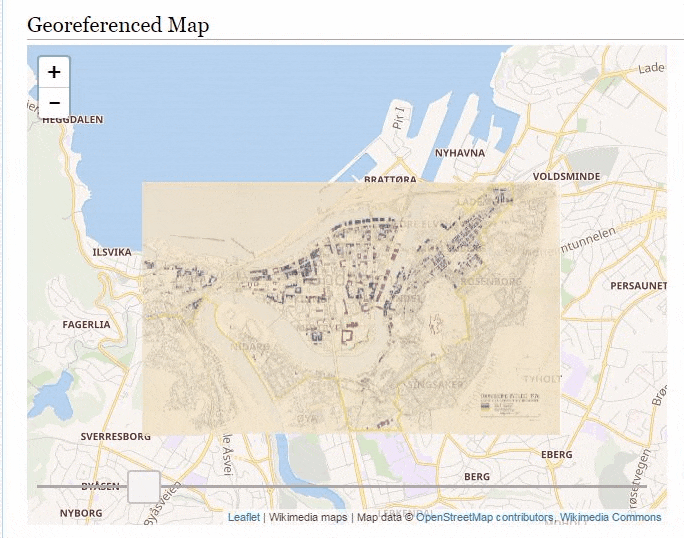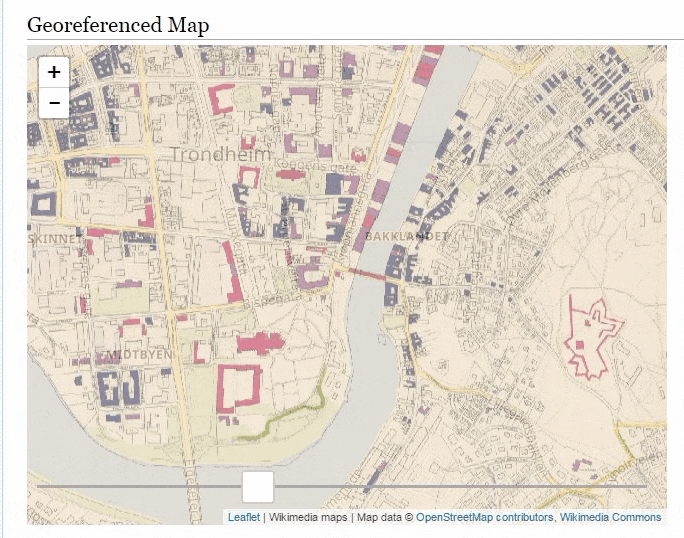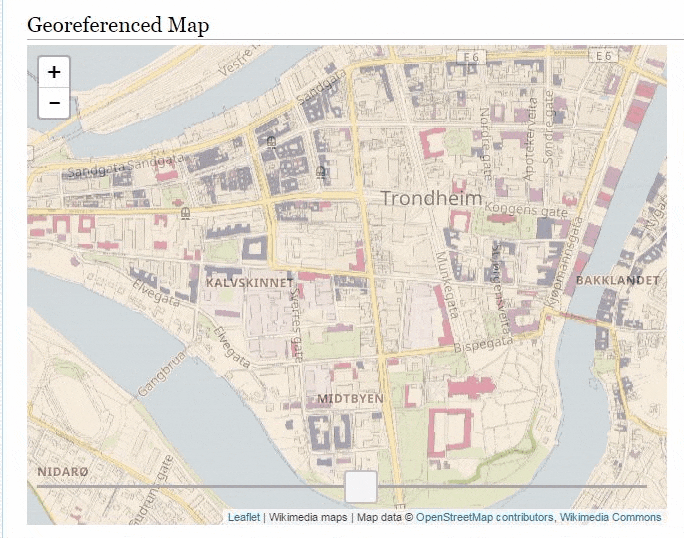
So a while ago I wrote a gadget which would embed any georeferenced map directly on it’s Commons page. To install it import it by adding importScript('User:Abbe98/warper-viewer.js'); to your common.js file.
Then visit a georeferenced map, here is a few suggestions:
It’s quite addictive browsing the maps.
_(13307511695).jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}