16th September 2020
On my main computer, there are essentially three things that change regularly and aren’t backed up to a could service regularly. These three things are notes, browser bookmarks, and keys/passwords. To be able to back up these to external servers without the hassle, I wrote a Bash script a while back that allows me to type backup anywhere in my terminals to quickly get an encrypted zip containing these files.
The following code can be placed in a file named backup inside of /usr/bin and once you have made sure your everyday user is set as the owner you are good-to-go. Typing backup should prompt you for an encryption key and following that you should have two backup files in your current directory. You should of course change the file paths as needed for you, the example is for my use of Joplin, Firefox, and Seahorse.
Some Final Notes
- Don’t name the file “backup” (I haven’t) give it a name only you know.
- It’s not using zip’s built-in encryption nor should anyone.
#!/bin/bash
echo "Starting backup"
echo "Locating Firefox profile."
FIREFOX_PROFILE=$(find ~/.mozilla/firefox/ -maxdepth 1 -type d -name *.default | head -1)
echo "Firefox profile found at: ${FIREFOX_PROFILE}"
SSH="${HOME}/.ssh"
KEYS="${HOME}/.local/share/keyrings"
BOOKMARKS="${FIREFOX_PROFILE}/places.sqlite"
NOTES="${HOME}/.config/joplin-desktop"
echo "Directories selected for backup:\n${BOOKMARKS}\n${KEYS}\n${SSH}\n${NOTES}"
echo "Zipping directories"
zip -r backupoutput.zip ${BOOKMARKS} ${KEYS} ${SSH} ${NOTES}
echo "Encrypting zip file"
gpg -c backupoutput.zip
echo "Done, remember to delete both files"
15th September 2020
Pywikibot does not yet have built-in support for writing Structured Data to Wikimedia Commons so to do so currently one needs to do it by posting JSON data to the Wikimedia Commons Wikibase API, this blog post will walk you through how to make the requests needed and how to structure the JSON to get it all working.
The minimal example presented here will check if the given file has a statement claiming that it depicts a hat and if not write such a statement.
First of you will need to have Pywikibot installed and all god to go, the following imports and code should run without error.
import json
import pywikibot
site = pywikibot.Site('commons', 'commons')
site.login()
site.get_tokens('csrf') # preload csrf token
Next up let’s turn a pagename/filename into a MID, think of a MID as Wikidata’s QID but for Wikimedia Commons. The MID happens to correspond to Mediawiki’s “pageid”.
page = pywikibot.Page(site, title='Konst och Nyhetsmagasin för medborgare af alla klasser 1818, illustration nr 44.jpg', ns=6)
media_identifier = 'M{}'.format(page.pageid)
Next up, we need to fetch all existing structured data so that we can check what statements already exist. Here is the first example where we need to use Pywikibot’s internal API wrapper “_simple_request” to call the Wikibase API, you could do the same with a regular HTTP library such as requests.
request = site._simple_request(action='wbgetentities', ids=media_identifier)
raw = request.submit()
existing_data = None
if raw.get('entities').get(media_identifier).get('pageid'):
existing_data = raw.get('entities').get(media_identifier)
Next, let us check if depicts (P180) got a statement with the value Q80151 (hat), if so exit the program.
depicts = existing_data.get('statements').get('P180')
# Q80151 (hat)
if any(statement['mainsnak']['datavalue']['value']['id'] == 'Q80151' for statement in depicts):
print('There already exists a statement claiming that this media depicts a hat.')
exit()
Now we need to create the JSON defining such a claim, it’s verbose, to say the least. You can add more claims by appending more objects to the “claims” array. To get an idea of what these JSON structures can look like you can add structured data using the Wikimedia Commons GUI and then look at the resulting JSON by appending “.json” to the media’s URI. It might be particularly interesting to try out qualifiers and references.
statement_json = {'claims': [{
'mainsnak': {
'snaktype':'value',
'property': 'P180',
'datavalue': {
'type' : 'wikibase-entityid',
'value': {
'numeric-id': '80151',
'id' : 'Q80151',
},
},
},
'type': 'statement',
'rank': 'normal',
}]}
Now, all we need to do is to send this data to the Wikibase API together with some additional information such as a CSRF token the media identifier, etc.
csrf_token = site.tokens['csrf']
payload = {
'action' : 'wbeditentity',
'format' : u'json',
'id' : media_identifier,
'data' : json.dumps(statement_json, separators=(',', ':')),
'token' : csrf_token,
'summary' : 'adding depicts statement',
'bot' : True, # in case you're using a bot account (which you should)
}
request = site._simple_request(**payload)
try:
request.submit()
except pywikibot.data.api.APIError as e:
print('Got an error from the API, the following request were made:')
print(request)
print('Error: {}'.format(e))
That should be it, you can now use this example to create your own wrapper around this functionality to make it usable in batch operations.
In case you want to write SDC with the mwoauth/mwapi libraries instead of Pywikibot you can look at this Flask application built for the Roundtripping project to get a hint.
24th August 2020
Things
Took part in the weekly competition on the Swedish Wikipedia about adding video material to articles. In total, I added videos to 44 articles, thanks to the Wikidata query service.
Did a Wikidata live-stream with Jan again, I highlighted property 5991 “carbon footprint” hoping that usage will go up! You can watch the recording on Youtube.
Following a two day hike this weekend I (finally (buried a hatch?)) got a iNaturalist account.
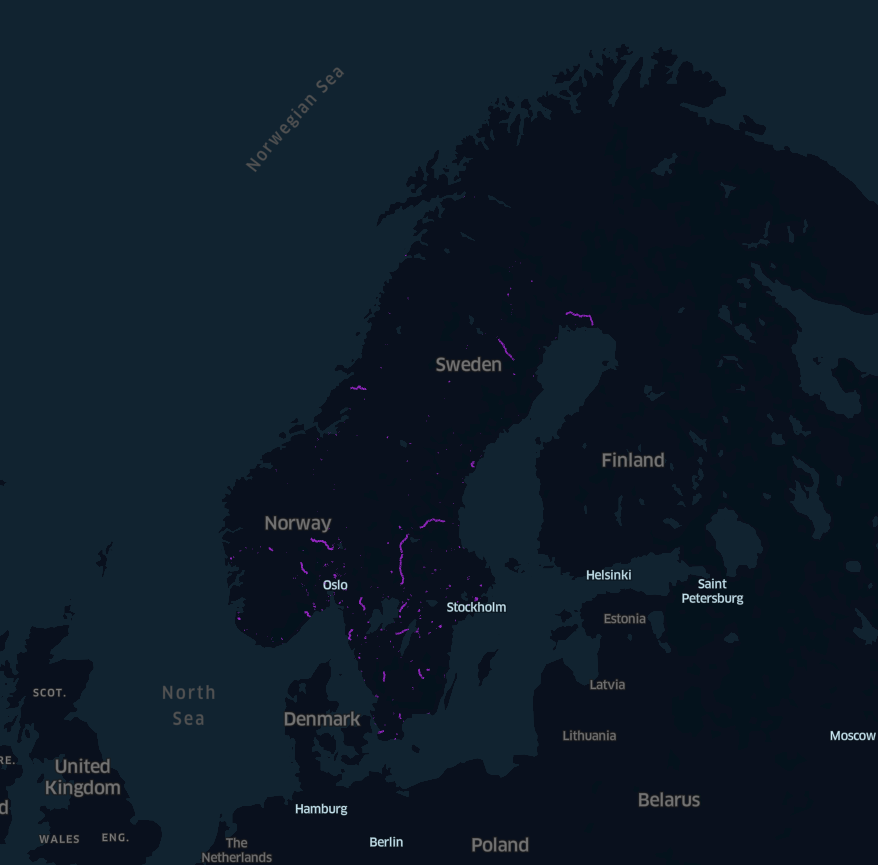
Visualized disused railways in Sweden and Norway over lunch one day.
Reading
Wikimedia Foundation Annual Carbon Footprint Report
Python Hash Tables: Understanding Dictionaries - a dive into how Python dictionaries are built on top of hash tables.
Jupyter Notebook REST API - While researching if there is an (easy) way to turn papemill notebooks into APIs if found Jupyter Kernel Gateway which took me halfway to what I wanted.
Apple VS Epic - This is such an interesting case. Well prepared lawsuit from a rich activist that wants to change the system while Apple in parallel faces investigations already.
New in PHP 8 - each time these “new in PHP” articles come around I get an urge to get back into some PHP development (other than MediaWiki), same this time.
Cool things around the internet
The Open Restitution Project - This project looks to collect and aggregate restitution data from an African perspective. They are currently looking for partners.
Final notes
“Recently” is a new format I’m trying out, inspired by my reading lists that have been up and down for years. The intention is to be broader and include things I and others have done that won’t make it into a post on its own.
9th August 2020
Two years back I wrote about runor.rocks a small service I built in five minutes that redirects you to a random article about a runestone. An issue with the solution was speed so when I wanted to explore Serverless a while back it was the perfect small project to revisit.
The task at hand was very simple, given a set of URLs redirect to one of them randomly. Small task and perfect for experimenting with Serverless.
I went with Cloudflare Workers as the serverless option, mainly because I’m already a Cloudflare customer.
The first thing that impressed me was its Editor, I could code and test the entire service directly on the website, sure it’s a very simple script but often the first barrier is the one that matters the most. Deploying isn’t a thing saving the file and done, for a critical service I imagine you would need a local or staging environment but compared to the same for a VPS it’s a breeze.
My script ended up looking like the following:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
});
async function handleRequest(request) {
const runes = [
'https://en.wikipedia.org/wiki/S%C3%B6dermanland_Runic_Inscription_245',
'https://en.wikipedia.org/wiki/Jelling_stones',
'https://en.wikipedia.org/wiki/Kirkjub%C3%B8ur_stone',
'...',
];
const redirect = runes[Math.floor(Math.random() * runes.length)];
return Response.redirect(redirect, 307);
}
One thing I wanted to think about when I explored Serverless were the vendor lock-in, now after having this and two other of my hobby projects migrated to Cloudflare workers my concern is mostly migrated. If one uses it for small microservices that doesn’t need heavy integration with storage I would consider it. I would however not use a similar service from a small business, startup, or Google because one’s code just can’t run anywhere in case they shutdown.
My overall impression is very good it eliminates many of the maintenance and deployment hurdles and the amount of lockin is okay for basic microservices in my opinion. In many projects, I would however consider them technical debt.
Since this experiment Cloudflare Workers has become even more inviting, things like elimination of cold starts and Python support will make it stay as my go-to option for serverless.