21st September 2021
Having self-hosted various tools and services for a few years, I now believe I got a solid home server setup that covers almost all of my use-cases, and therefore I thought I would share my current setup.
Core services
Pi-hole
While the common use case for Pi-hole is content and ad-blocking I use it as both a DNS and DHCP Server in addition to content blocking. It essentially keeps most of my network management in one place. Pi-hole is a must-have piece of software for me nowadays as it makes browsing faster and saves a lot of battery for all of my devices.
Apache/WebDav
Apache and in particular its WebDav module is what I use for file sharing and synchronization. WebDav might be an old and scray protocol, but its ecosystem is great. WebDav just works with all kinds of clients most importantly for me with Nemo(file manager) and Joplin(note-taking).
Rclone
I use Rclone to make backups of my WebDav enabled files as well as some other services.
Jellyfin
I used to self-host Calibre-web for my eBooks, but after a couple of pull requests to the Jellyfin user interface, I now use it as a more general-purpose system. Today I use it to host eBooks, photographs, radio shows, and papers.
In addition to the services above I also host a few major technical tools like JupyterHub, Jena Fuseki / Thor SPARQL editor, and Git.
Wishlist
Firefox sync
I don’t use Mozilla’s sync service but instead, I have a backup script to backup my bookmarks, history, etc. It would however be nice to have a live sync service for my own devices. The open source service Mozilla provides is however rather complex and nothing I feel like hosting at this point, especially as I don’t have a current need for Docker.
Hardware
Everything is hosted on a Raspberry Pi 3b+ that boots from an SSD. A second Raspberry Pi 3b+/SSD hosts Rclone and periodically makes backups of the main Pi’s WebDav service.
8th September 2021
It has been more than 17 months since Jan Ainali asked if I wouldn’t be up for some live-streamed Wikidata editing. It seemed like an insightful and valuable thing to do. Now, over 50 episodes later, we have showcased more than 30 community tools, issued over 100 SPARQL queries, and even so, we don’t lack ideas for future content.
From day one, we have been using StreamYard and been broadcasting to a handful of platforms. Having no experience at all with streaming, StreamYard has been a joy to use. With a helping hand from Jan, I could get around the basics within a few minutes. Other tools I combine it with are Wikimedia’s URL-shortener to easily share URLs and Firefox running a separate profile for the window I share. I often also have a separate Joplin window where I have notes and URLs I might need during the broadcast.
Finding Content
While I personally could make 50 episodes of me editing historical railway systems and making maps with the same tools over and over, I try not to. I think three main things help us broaden our content beyond our own ideas.
Jan is particularly quick when it comes to picking up new tools that the community has come up with, I can’t keep up myself and it has happened that I have showcased a tool as “new” when in fact it has been around for several years.
2. Awareness days
Awareness days have been a great way to explore and edit new types of content. It’s so useful that we even created an awareness day calendar using Wikidata and SPARQL on stream once.
3. Events
There are plenty of themed events relating to Wikidata and Wikimedia which provide both content and new audiences for both us and the events.
What Makes a Good Episode
Initially, I improvised and did everything live, and I still do that sometimes especially if I focus on editing/Wikidata content rather than on tools/workflows. An episode for which I have prepared a set of guiding points makes for better content. I guess my average preparation takes about 45 minutes. If I prepare or not depends much on if I find the time and motivation during the week. The most notable difference between a well-prepared episode and a less prepared one on my end is how many times I repeat the same things. Repeating something I just said is something I find myself doing when I improvise on the fly, if I, on the other hand, need to move straight to the next point the repetition does not occur.
Visual reusable examples and visualizations make good popular content, while it appears like fancy graphs and maps draw the most viewers and views, just a few users picking up a powerful editing workflow or tool might be of much greater benefit to Wikidata and its community. We need a mix of these and I hope we got that mix.
The pace is tricky, especially when one does semitechnical things while one wants to give viewers the time to make comments. It’s hit or miss on my end and I have yet to figure out a good way to manage it, especially as it’s so dependent on the content.
Things to Improve
1. Backlog of Prepared Content
In the future, I would like to build up a “prepared content” backlog so that I can be confident in the quality even during weeks when I have a lot on my plate.
2. Blog Posts Describing Advanced Workflows
It’s not unusual that Jan or I share quite advanced workflows and while a stream might be a good way to showcase it, it might not be the best medium to help someone adopt it. I have once or twice created write-ups for showcased workflows but maybe what I should do is to do so before an episode so I can share it at the end of the stream.
Every now and then, we get a suggestion from the community for a topic or thing to talk about, but we could have more of this. No matter if you discover a tool that you found useful or if you made it, share it with us. We want to let more people know about it! We should prompt this in more places.
4. Increase the interaction with viewers
One pattern I imagine I observe is that if one person makes a comment that we can bring up on screen it’s more likely that someone else will too, even if it’s just a “Hi!”.
I’m yet unsure of what makes good content that encourages interactions with viewers. Maybe it’s good old editing where we are far from experts on the data modeling we face so that the audience can suggest things that we can use and improve. Maybe we should talk more about the weather.
Where You Find Our Episodes
We tend to stream on Saturdays at 20:00 UTC+2. The best way to get notified is by subscribing to the Wikipedia Weekly Network on YouTube. Our past episodes are listed over at the Wikimedia Meta-wiki.
17th November 2020
A couple of months back I discovered the SPARQLing Unicorn QGIS Plugin and it has been super useful for both data visualizations and Wikidata editing.
After installing it adds a new option under the “Vector” menu item in QGIS. Its interface allows one to access and query a set of predefined SPARQL endpoints including Wikidata as well as pointing to a custom endpoint or RDF file.
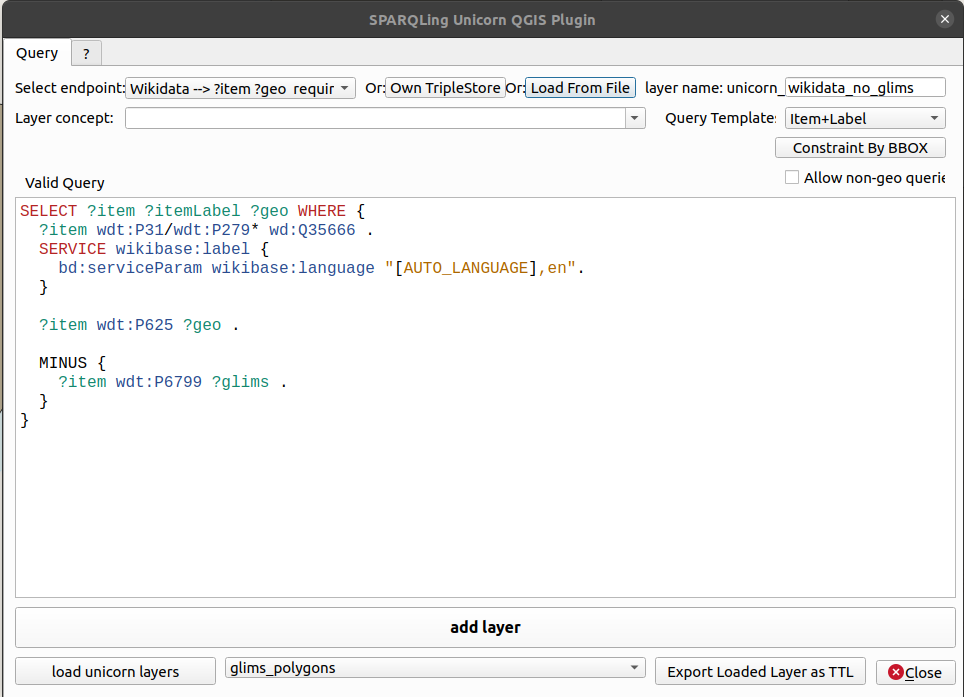
One of my use cases has been to fetch all glaciers in Wikidata missing GLIMS identifiers and then add a GLMIS layer from the official Shapefiles so I can visually see the overlap.
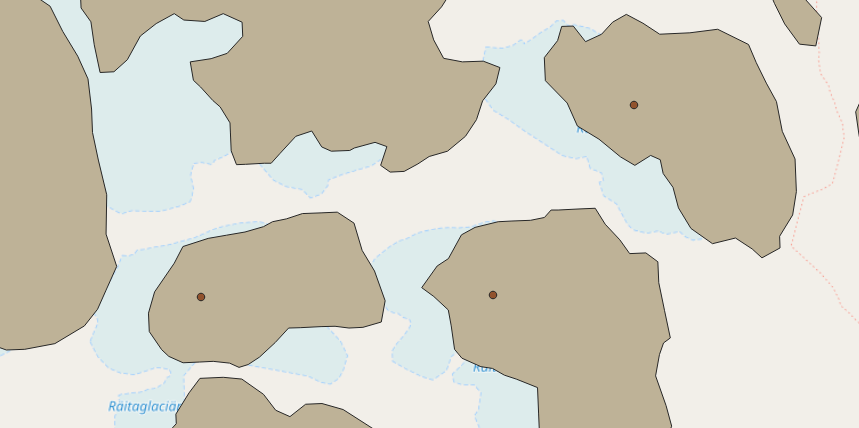
I hope you will find this plugin useful as well.
17th September 2020
Just the other day I decided to take a stab at an old StackOverflow questing about getting random results from SPARQL.
The most obvious solution might first appear to be using SPARQL’s built-in RAND() function and order by that random number:
SELECT ?s WHERE {
?s ?p ?o .
BIND(RAND() AS ?random) .
} ORDER BY ?random
LIMIT 1
This could have been perfectly fine if it weren’t for SPARQL engines trying to be smart and statically evaluating the third line. At the second result row, most SPARQL engines see a line and “thinks”, “oh this is identical to what I did on the row before this one, the result must be the same”.
This can be illustrated by the Wikidata SPARQL query below, note how all rows have the same ?random value:
SELECT ?item ?itemLabel ?random WHERE {
?item wdt:P31 wd:Q11762356 .
BIND(RAND() AS ?random) .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE], en" . }
} ORDER BY ?random
LIMIT 100
# comment, change this before each run to bypass WDQS cache
A common solution to this issue is ditch RAND() entirely and instead hash a value in each row and sort it by the hash.
SELECT ?s WHERE {
?s ?p ?o .
BIND(MD5(?s) AS ?random) .
} ORDER BY ?random
LIMIT 1
This will however generate the same order each time as the hashes are entirely based on the result data. Illustrated by the example below:
SELECT ?item ?itemLabel ?random WHERE {
?item wdt:P31 wd:Q11762356 .
BIND(MD5(STR(?item)) AS ?random) .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE], en" . }
} ORDER BY ?random
LIMIT 100
# comment, change this before each run to bypass WDQS cache
The solution is to combine the two. The use of hashed result data makes sure the SPARQL engine can’t statically evaluate RAND() and the fact that RAND() is therefore executed each time helps avoid the selection bias.
SELECT ?s WHERE {
?s ?p ?o .
BIND(SHA512(CONCAT(STR(RAND()), STR(?s))) AS ?random) .
} ORDER BY ?random
LIMIT 1
Here again illustrated with a Wikidata query:
SELECT ?item ?itemLabel ?random WHERE {
?item wdt:P31 wd:Q11762356 .
BIND(SHA512(CONCAT(STR(RAND()), STR(?item))) AS ?random) .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE], en" . }
} ORDER BY ?random
LIMIT 100
# comment, change this before each run to bypass WDQS cache
Know a better way to retrieve random results from SPARQL? Let me know on Twitter!